
#018: Lessons Going from Snowflake to BigQuery
Nov 05, 2022Snowflake was my intro to cloud databases and where I’m most comfortable.
But my last 2 clients used Google BigQuery.
I’d be lying if I said there wasn’t a learning curve.
Today, I want to share 3 things I’ve learned in the last 6 months to help you feel prepared for either platform:
- Naming conventions
- Compute scaling
- Cost structure
BigQuery has unique naming conventions
Snowflake feels similar to other databases regarding terminology.
But on BigQuery, you won’t see terms like “database” or “schema”.
Rather than critique, embrace these differences.
Data modeling is the same regardless of what you call the objects.
Example: BigQuery Project > Dataset = Snowflake Database > Schema.
Compute scaling showed me what “serverless” meant
Adjusting computation impacts both cost and performance.
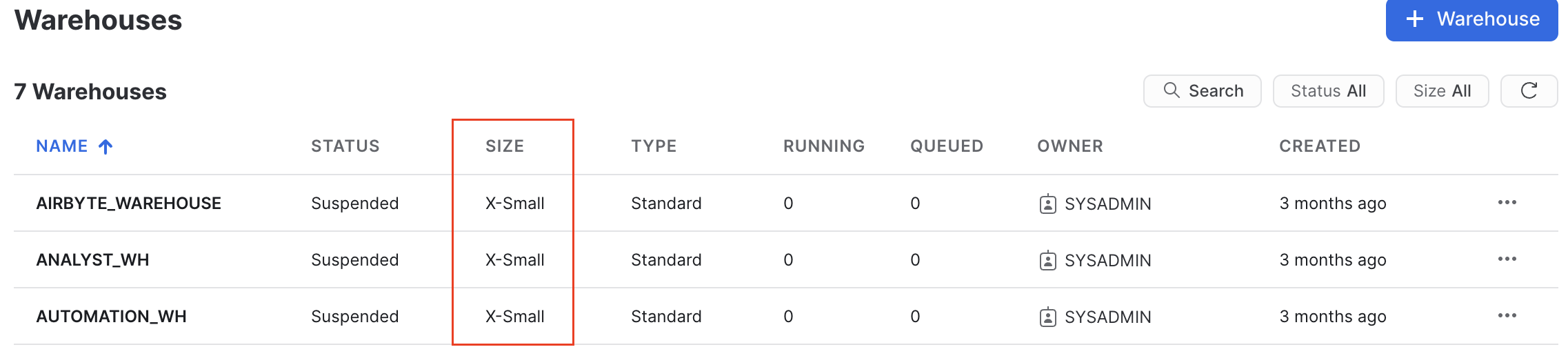
On Snowflake, you create separate objects and set auto-resume/suspend.
But on BigQuery, all scaling/suspending is done for you.
This hands-off approach felt odd at first but actually became quite nice.
Example: On Snowflake, you must select “warehouse” sizes.
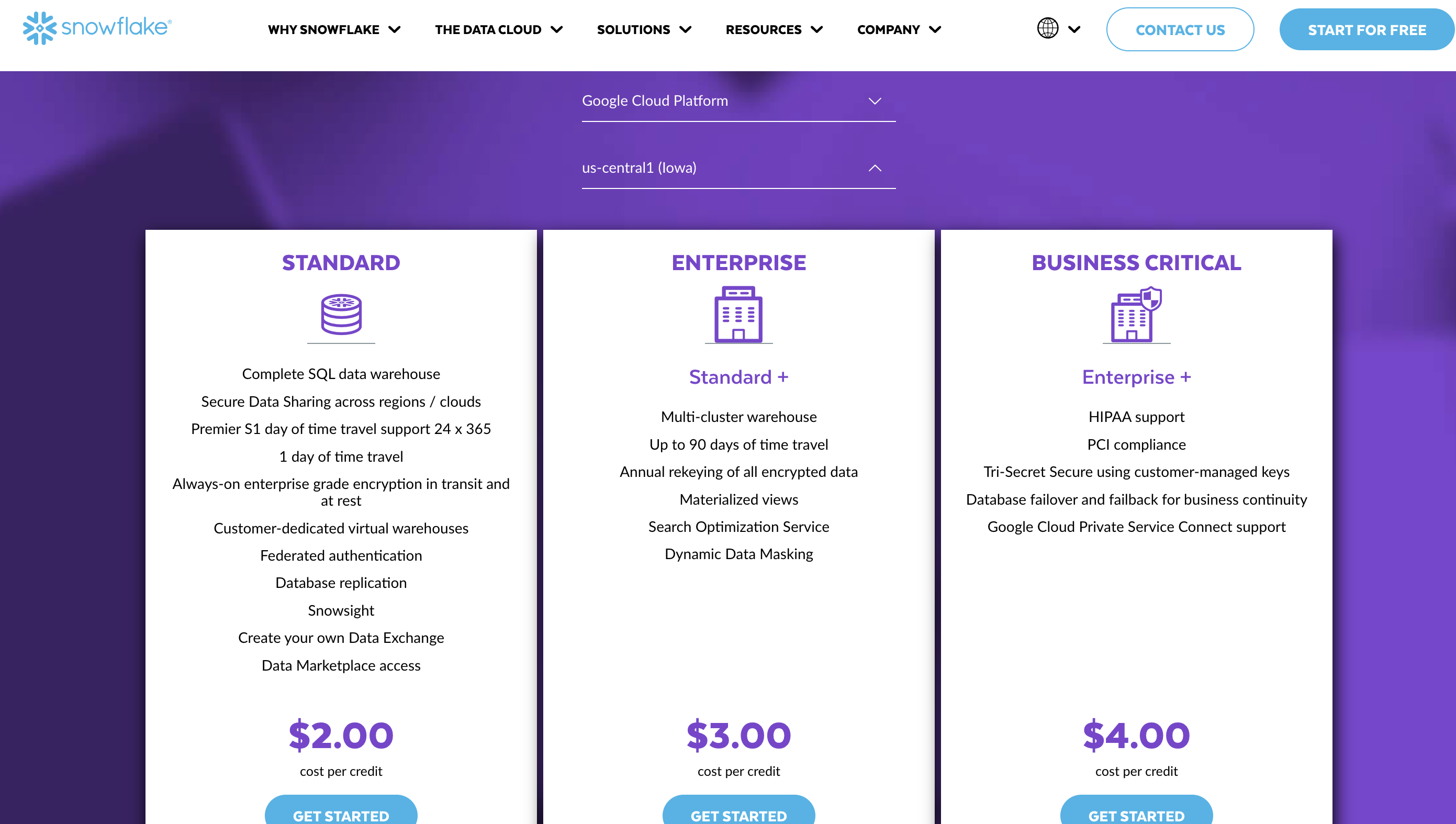
Snowflake charges by compute time, BigQuery on bytes processed
The different cost structures are confusing.
It’s a big decision factor and might impact your build strategy.
Tip: On BigQuery, implement partitions and/or clusters.
This makes queries more efficient, reduces bytes processed and therefore costs.
Example: Snowflake charges by credits, regardless of processed bytes.
Being a well-rounded engineer requires flexibility.
Understanding terminology, scaling and cost structures will help you navigate both of these great platforms.
Get More Resources & Connect With 2,700+ Data Engineers
Join a free private community to access resources, templates, and training designed to help you build modern data architectures with confidence
