
#010: Life after SQL: Key Topics for Modern Engineers
Aug 14, 2022Data engineers today are expected to do much more than write SQL queries.
You’ll often own areas of automation, infrastructure, integrations, security and more.
It can feel overwhelming at first.
But also remember that nobody knows it all.
In this week's edition, you’ll learn about 3 key topics to prepare yourself for the wide range of responsibilities as a modern engineer.
Let's discuss.
Containerization
Containers are essentially mini-versions of a computer system…within a computer.
They are abstracted on top of the physical infrastructure and can be easily created, destroyed, rebuilt over and over through just a few commands.
The most common tool used for this is Docker.

You can host many container applications on the same physical machine.
And each will be based on a specific set of instructions, aka an “image” file.
This means you can be sure a container is created the same way every time.
This has huge benefits and has become a key component of data platforms.
Let’s discuss 3 common places you’ll see them pop up.
Automation & CI/CD
In order to continuously release code, you need to be able to test it.
To properly test, you also want to be sure your environment is consistent.
A great way to accomplish this is through containers!
Configure an environment you want and re-test over and over.
Once you're done testing, you can close down the container and move on.
Self-hosting
How many times have you tried to install a new tool on your local machine but run into issues?
Maybe it’s weird dependency issues or you’re on a different operating system.
It’s incredibly annoying.
But once again, containers to the rescue!
Many open-source tools (ex. Airflow, Airbyte, etc.) have options to host the tool directly in a container.
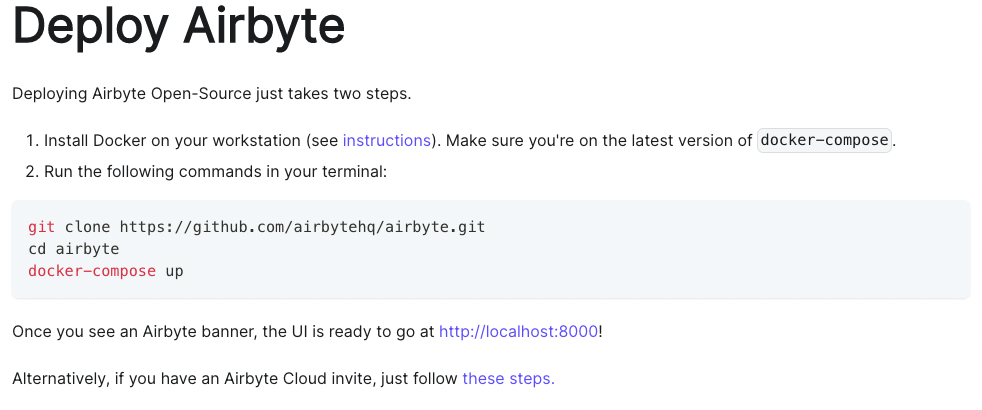
That way you can avoid the tedious steps of setting up your own environment and instead run a few commands to get started.
Orchestration
As you might imagine, it’s pretty easy to start creating a ton of containers.
And in an enterprise environment, handling all of these deployments is critical.
You also want to be sure production containers are always running.
To handle that issue, there are container orchestration tools.
A common example is Kubernetes and may be something you need to monitor.
Networking
Networking plays a major role in how your data tools and users will connect with each other.
Cloud environments
Cloud applications are great in that you avoid self-hosting.
However, we can’t forget this means they’re physically being run on somebody else’s server.
The only way to access them is over a network/internet.
Understanding concepts like IP addresses, ports and endpoints can help facilitate any potential issues that arise.
Security & Firewalls
Whether on the cloud or a local network, you’ll typically have some level of security (hopefully).
For example, you can block access to a database server to anybody outside of a specific IP Address range.
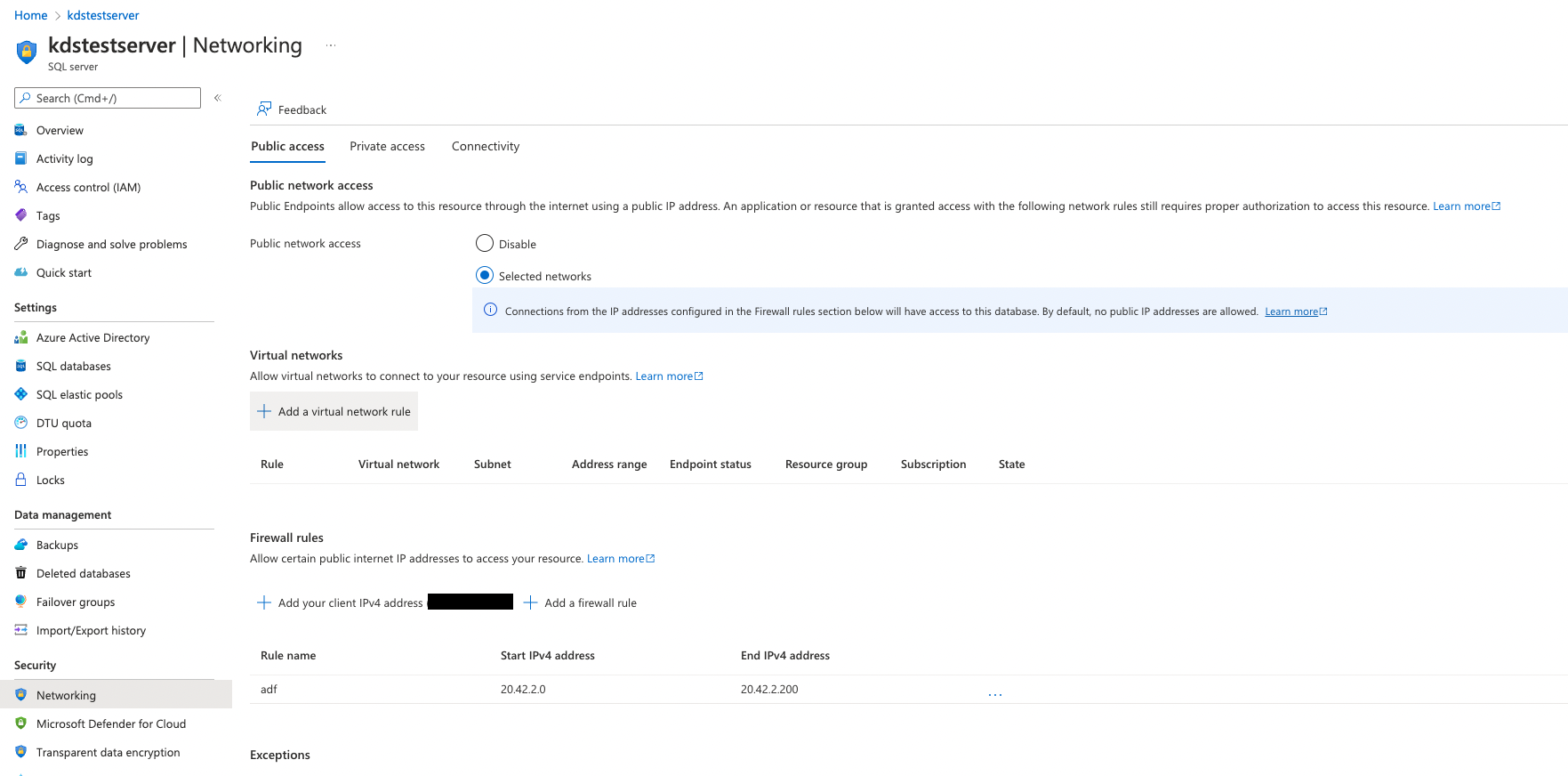
This is networking in action and is another reason to be familiar with the concepts mentioned above.
Infrastructure
The third topic is infrastructure which to me represents the overall maintenance of your data architecture.
Roles & Permissions
Creating roles, assigning users and granting permissions is a common task of infrastructure management.
Perhaps you’re familiar with Azure Active Directory
This is a common way to manage this for the Microsoft suite of products.
But from a data team perspective, this also includes managing database roles/permissions, cloud applications, etc.
Integrations
A modern data architecture consists of many different components.
And by default, most of them don’t talk to each other.
At the very least they’ll require at least a little bit of setup to make it happen.
This type of configuration between tools is like connecting physical machines in a production facility.
It’s the job of the engineer to make sure they are all working together, in the right order and producing the expected output.
Infrastructure as Code (IaC)
Making ad-hoc permission changes is really tempting and usually the fastest way to get it done.
But I think we can all agree that doing things that way is not going to scale well.
You might forget you made the change or, worse, nobody else knows it happened.
A great way to keep everything organized is to manage it in code.
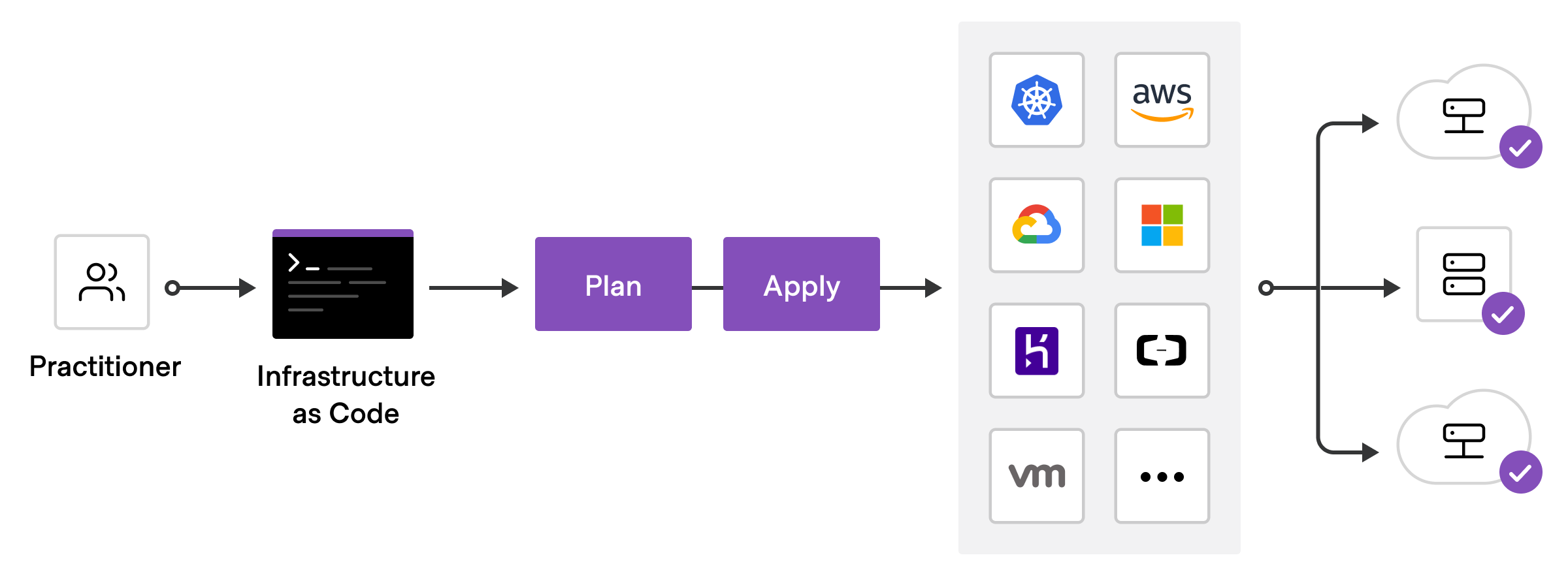
You can then version control all changes and easily re-create your environments if needed.
A great tool for this is Terraform, which happens to also be open-source!
Of course good hands-on SQL skills are still a must-have for data engineers.
But the modern data landscape requires much more.
You don’t need to master all of these things at once (I’m still learning myself).
But now you know about 3 topics to help you take that next step in your learning.
Get More Resources & Connect With 1,000+ Data Engineers
Join a free private community to access resources, templates, and training designed to help you build modern data architectures with confidence
