
#003: 3 Reasons You Should Always Use Database Roles
May 08, 2022More security. More cost savings. More automation.
In today's post you'll learn how database roles can influence all three and how understanding this topic can separate you as a more senior-level contributor.
# 1: More Security
It may sound obvious, but not all data should be visible to everyone.
Two common ways to leverage roles to restrict access are through:
- Object level security
- Row level security
Object Level Security
With object level security you grant a role permission to individual objects (ex. database, schema, table, etc.).
Each role is then composed of specific users.
If a user is not in a role, he/she will therefore not have access or visibility to the object.
It's a good practice is to create roles specific to any third-party applications or processes.
For example, Fivetran or dbt may have their own (or shared) role with restricted access.
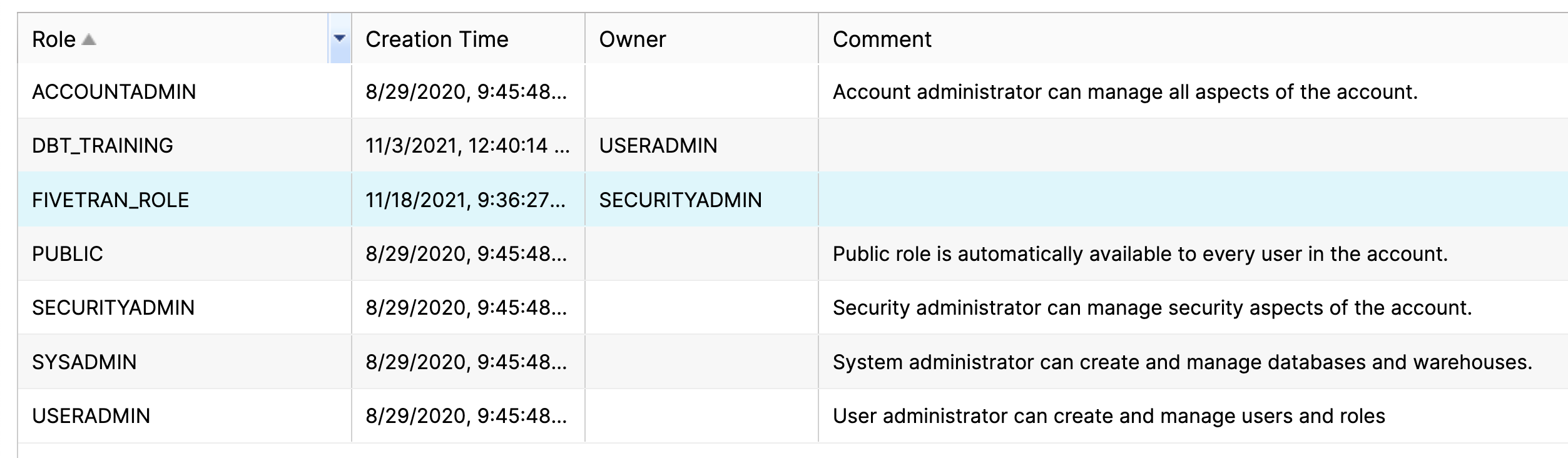
In this scenario, first create a service account user for each process and then assign them to a restricted role.
Another common practice is to create cascading roles where roles will inherit another (lower) role's permissions + a little bit more.
For example, Analyst > Developer > Manager > Admin
This allows you to group your users based on access level.
Somebody new joins a team?
Rather than setting permissions for that user on every individual object, simply add them to an existing role and you're all set.
Row-Level Security
For row-level security, you can go a step further and restrict access to individual records.
In tools like SQL Server Analysis Server (SSAS) or Power BI, you can configure your data model to run a check in real-time (using DAX) to determine what a user should/should not see.
In the below example, users in the role “SalesTerritoryUsers” will be restricted based on the value of the column “SalesTerritoryKey”.
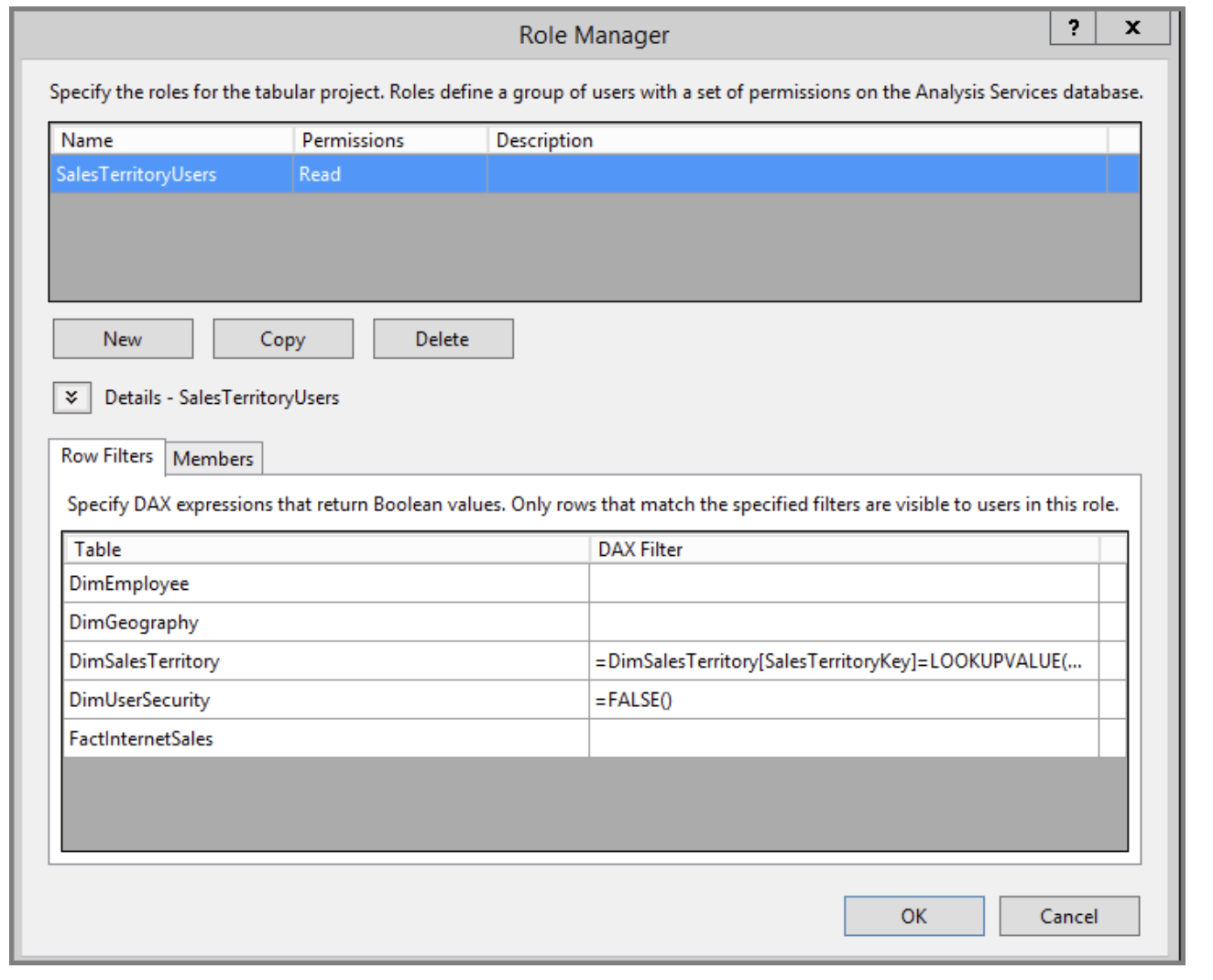
If a user in this role tries to look at a dataset including restricted data, the model will simply filter it out before it gets to them.
This applies to JOINs as well (assuming relationships are correctly defined).
But this is only feasible if you have your roles properly set up.
You should avoid creating conditions for individual users.
This won't scale well and will eventually result in technical debt when they leave.
# 2: More Cost Savings
Think about how you view your personal spending habits.
If you only ever look at the total amount, you’ll have a hard time knowing where specifically you might be over-spending.
The same can be said for monitoring your data architecture spend.
Most modern databases now separate computation vs storage costs.
With computation being by far the more expensive part.
Because of this separation, we now have the ability to create multiple compute objects.
Fortunately, tools like Snowflake allow you to see the costs broken down by object.
(Snowflake uses the term “Warehouse” to refer to their compute objects.)
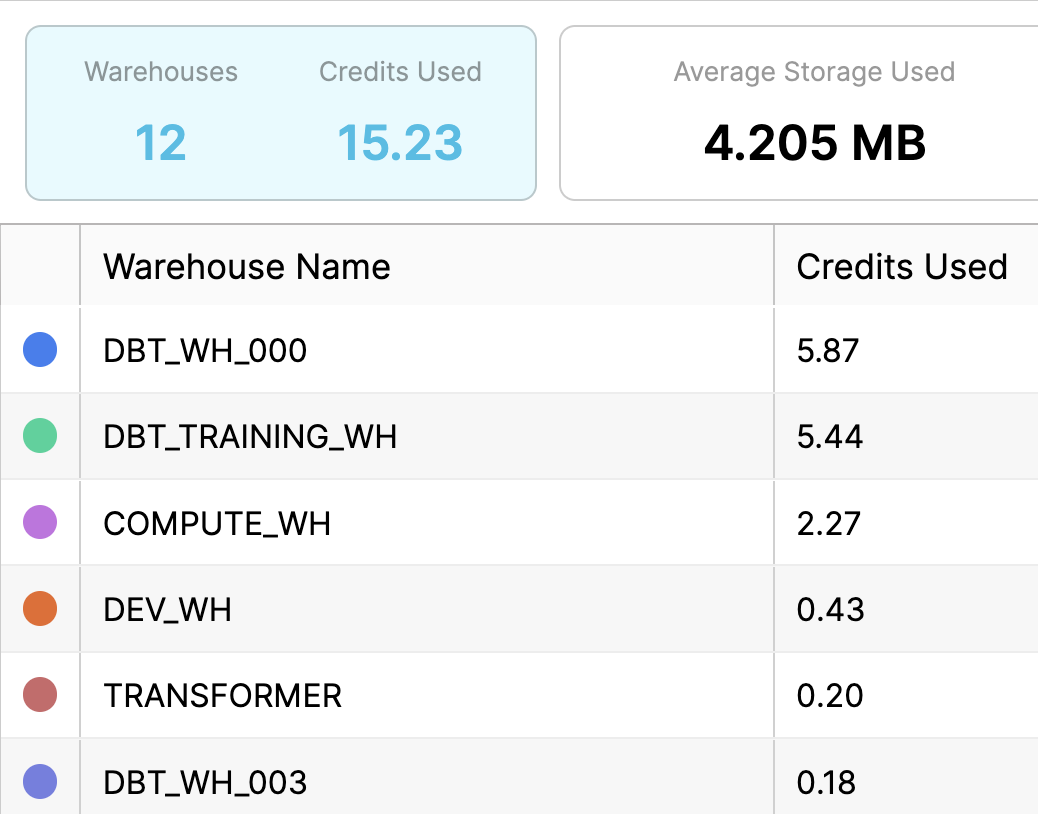
As mentioned in the first point - we can align roles to objects.
Assuming we properly manage our roles, we can make assumptions about our costs by knowing which roles have access to it.
If we notice one compute cost getting out of hand, we can quickly identify the related process and act accordingly.
# 3: More Automation
Many companies already implement some sort of user group management (ex. Active Directory).
And usually “groups” or “roles” are already declared there.
While most of us know about Single-Sign-On (SSO), another benefit is the ability to automatically provision new users on other platforms (where applicable).
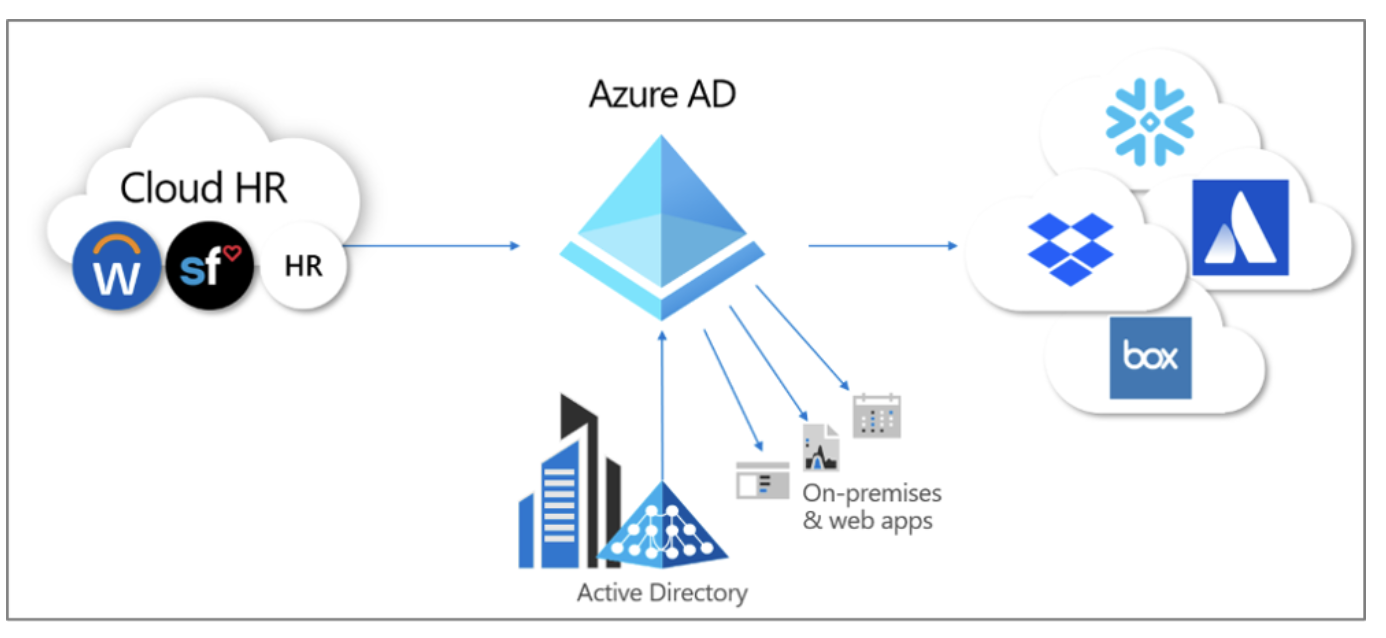
Let's assume we are all set with our Azure AD groups and have it configured to sync (aka reflect changes) in the database server.
Anytime a new user joins an AD group, we can sit back and let the automated sync process add them as a user tied to a specific role in our database server.
No need for additional requests or wondering what permissions they’ll have day 1.
To help more clearly track which AD groups are assigned to which DB role, consider implementing a tool like Terraform where you can version control and easily see it in code.
Some final thoughts:
Writing code and creating integrations is the fun part of data engineering, but doesn’t give you the full picture.
Understanding role management and its impact will allow you to think on a higher-level and see outside of just your individual task.
This is the type of thinking that is expected of senior level engineers and above.
Add this to your skillset and soon you’ll be presenting creative solutions in areas others may not have considered.
Get More Resources & Connect With 1,000+ Data Engineers
Join a free private community to access resources, templates, and training designed to help you build modern data architectures with confidence
