
#021: Why your data team needs version control
Nov 26, 2022The fastest route to problems is going straight to Production.
It feels easy in the short-term, but becomes a mess in the long-term.
But it’s shocking how many teams still do this.
So today, I’ll explain why your data team needs to be using Version Control so you can:
- Stop losing changes
- Release code faster
- Work better as a team
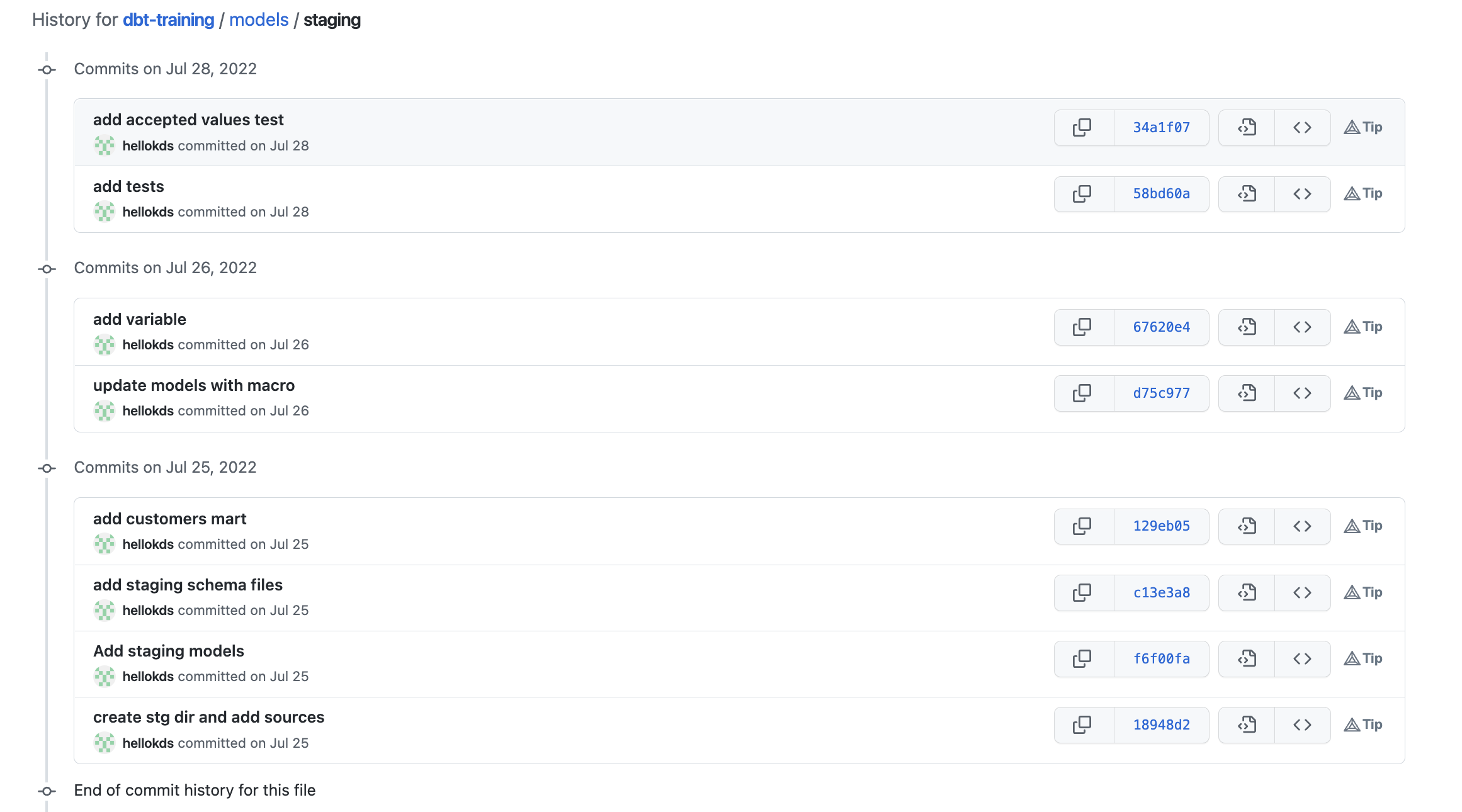
Version control tracks all historical changes
Imagine your teammate changes a bunch of code and releases it.
But 3 months later somebody asks you to revert everything back.
With version control, you’d be able to see every individual change.
Throughout history.
This makes it easy to identify updates and revert.
You’ll also never accidentally save (and lose) your work.
Example: Access all changes in any file
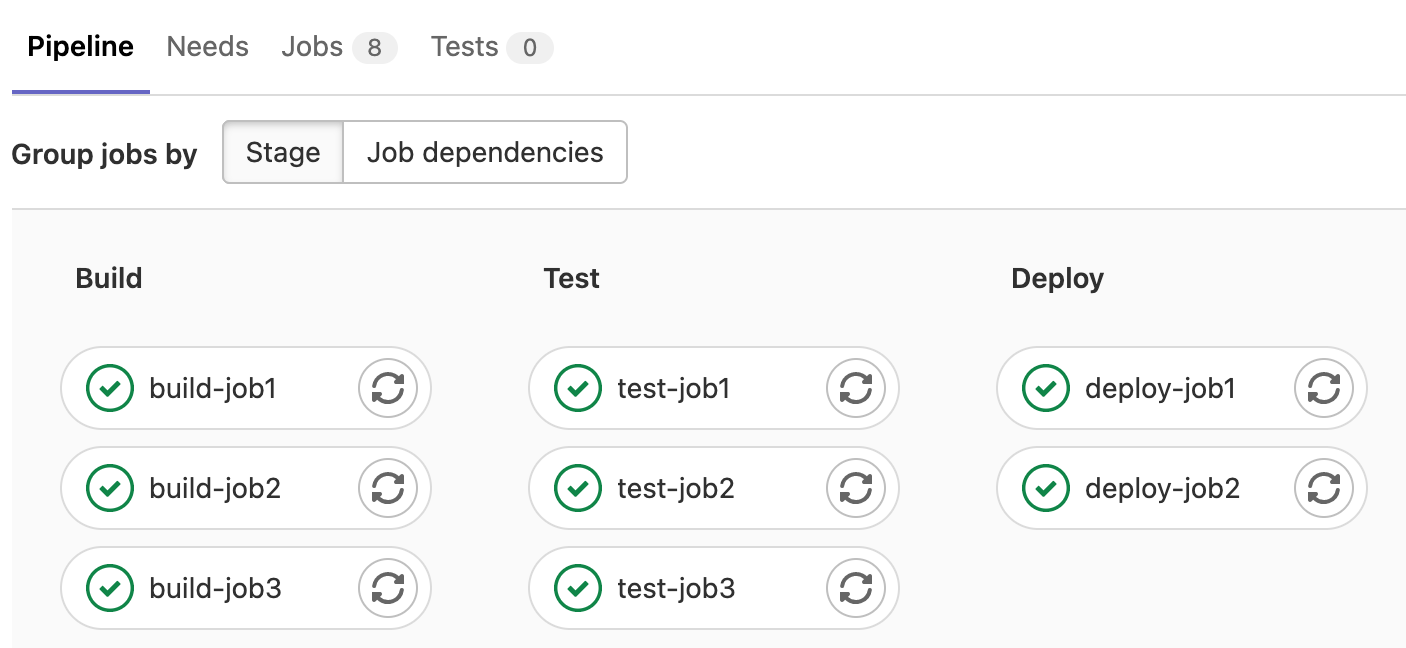
Version control helps automate your workflow
Raise your hand if you’ve stayed up late for a release night.
Moving code between environments is a huge task.
Especially when it all happens at once.
Instead, you can continuously deploy and test using platforms like GitHub.
This means changes are released faster and without all the attention.
No more late-night releases.
Example: Use GitHub Actions or GitLab Pipelines to deploy new changes
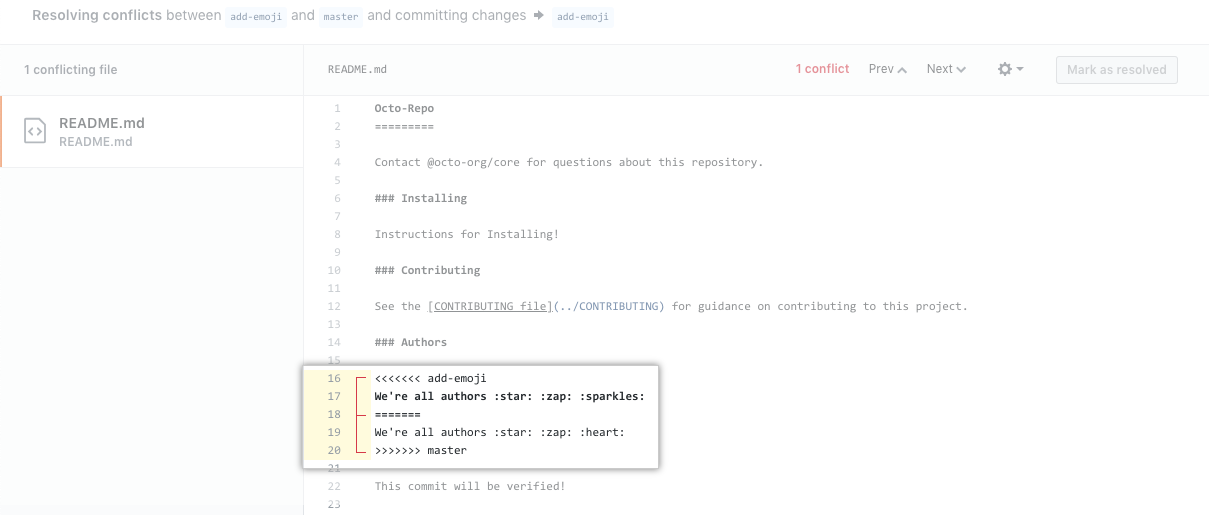
Version control makes it easier to work together
Working on a team is great…
Until two people need to change the same file.
You get code conflicts that might require a meeting to straighten it all out.
But version control (+ git) allows you to develop on your own and identifies conflicts for you.
No more accidentally overriding changes.
Example: GitHub forces you to resolve conflicts before merging.
Nowadays, there’s no excuse for not using Version Control.
With it, you can track history, automate your workflow and work better as a team.
Get More Resources & Connect With 1,000+ Data Engineers
Join a free private community to access resources, templates, and training designed to help you build modern data architectures with confidence
